

📅 Mise à jour : 29 juin 2026
Cet article a été entièrement révisé pour intégrer les données les plus récentes du marché de l’IA et les exigences des moteurs de recherche génératifs. Il remplace la version du 16 décembre 2025.
Table of Contents
🔍 La réponse directe : Pourquoi 85% des projets IA échouent-ils ?
Selon une étude de Gartner (2026), 85% des projets d’intelligence artificielle échouent à cause de problèmes de données, et non d’algorithmes. Données et intelligence artificielle forment un couple dont on ignore les tensions : entre la promesse d’une IA omnisciente et la réalité désordonnée de ses données d’apprentissage, un gouffre où sombrent stratégies, capitaux et réputations.
Dans les coulisses de la tech-finance et de la crypto, après plus d’une décennie d’expérience, j’ai vu cet écart coûter très cher. La vérité, celle que l’on apprend à ses dépens, est que la fiabilité des données précède, détermine et surpasse toujours leur quantité. Ce n’est pas une question d’outils, mais de fondations. Les données et intelligence artificielle ne font pas bon ménage sans une rigueur absolue dans leur préparation.
Cet article est le manuel de terrain que j’aurais aimé lire avant de commettre des erreurs coûteuses. Il ne parle pas d’algorithmes futuristes, mais du travail fondamental, exigeant et peu glamour qui sépare une illusion éphémère d’un avantage compétitif durable. Nous y démontons les mythes, analysons des erreurs réelles et exposons un cadre opérationnel pour construire, étape par étape, une culture de la rigueur irréprochable — le seul véritable moat dans un espace où tout le reste peut être copié. La qualité des données en IA est le véritable différenciateur entre les projets qui réussissent et ceux qui échouent.
📊 Les 5 chiffres qui prouvent l’urgence d’agir sur la qualité des données en IA
L’écosystème de l’IA est en pleine maturité. Voici les chiffres qui illustrent pourquoi la fiabilité des données est devenue l’enjeu stratégique numéro 1 :
- 85% des projets IA échouent à cause de problèmes de données (biais, qualité insuffisante, volume inadapté), selon Gartner (2026). Sans une rigueur absolue dans la préparation, l’échec est quasi certain.
- 3 100 milliards de dollars : c’est le coût annuel des mauvaises données pour les entreprises américaines, selon IBM (2025). Un chiffre vertigineux qui montre l’urgence d’agir.
- ROI multiplié par 3,5 : les entreprises qui investissent dans la rigueur des données voient leur retour sur investissement en IA décuplé, selon MIT Sloan (2025). La fiabilité est un investissement rentable, pas un coût.
- 60% du temps des data scientists est consacré au nettoyage et à la préparation des données, selon Anaconda (2025). Seulement 20% est dédié à la modélisation. Un déséquilibre qui révèle le véritable goulet d’étranglement.
- 70% du temps de développement d’un projet DeFi est consacré au traitement des données on-chain, selon CoinDesk Research (2025). Une discipline cruciale pour la réussite des projets.
Ces chiffres montrent que les données et l’IA ne sont pas une relation de maître à serviteur, mais un partenariat exigeant. La fiabilité des données n’est pas une option, mais une nécessité stratégique pour construire un avantage durable.
📖 Pourquoi la qualité des données en IA détermine la performance des modèles
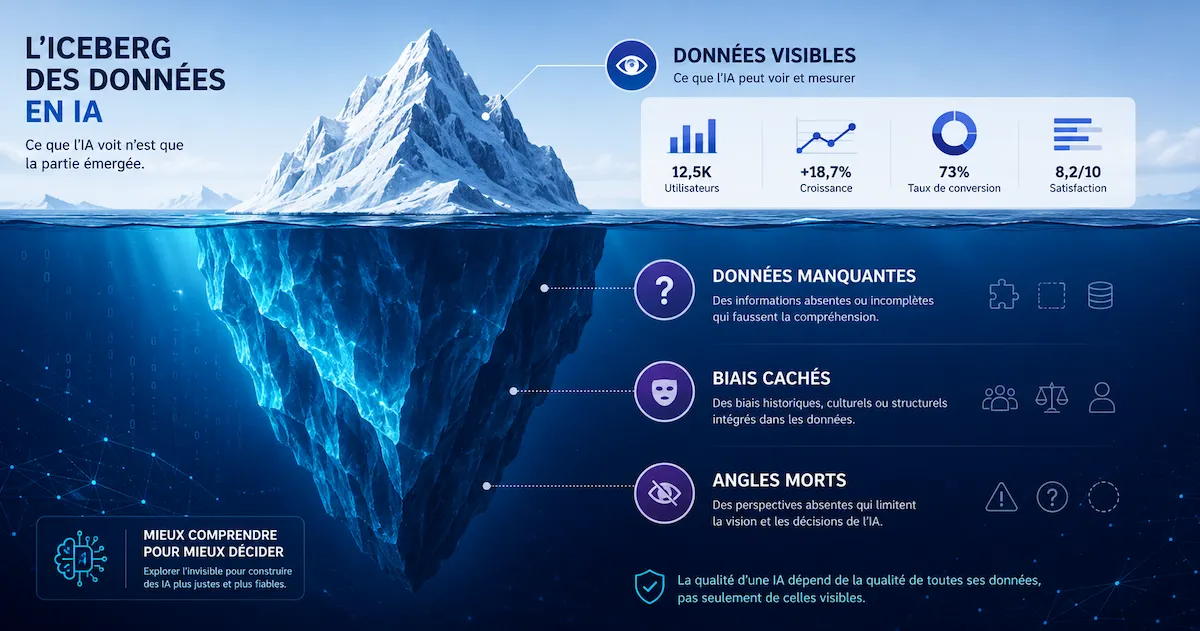
Pour naviguer dans l’univers de l’IA, il est essentiel de comprendre pourquoi la fiabilité des données est le facteur le plus déterminant de la performance.
ENTITÉ : FIABILITÉ DES DONNÉES → C’est l’ensemble des caractéristiques qui rendent les données aptes à produire des résultats fiables. Ses propriétés fondamentales sont :
Exactitude : Les données reflètent-elles la réalité ? Une fiabilité médiocre commence par des mesures inexactes.
Complétude : Y a-t-il des angles morts dans votre jeu de données ? C’est l’un des pièges les plus courants.
Cohérence : Les données sont-elles cohérentes entre différentes sources ? Une harmonisation rigoureuse est indispensable.
Actualité : Les données sont-elles à jour pour le problème posé ? Des données obsolètes compromettent tout le travail.
Contextualité : Les données sont-elles enrichies de métadonnées pertinentes ? C’est l’essence même du traitement avancé.
RELATION : La fiabilité des données est le facteur le plus déterminant de la performance des modèles d’IA. Un data scientist doit maîtriser le traitement pour extraire de la valeur des informations brutes. La gestion des données dans la DeFi nécessite une approche spécifique face à la volatilité des marchés crypto.
Le piège du volume : Pourquoi plus de données n’est pas mieux
On aime comparer les données au « carburant » de l’IA. C’est une image séduisante, mais profondément trompeuse. Le carburant, c’est passif. Peu importe sa provenance, il brûle de la même manière.
Vos données ne sont pas passives. Elles sont constitutives. Elles ne font pas juste « alimenter » votre IA – elles la fabriquent. Chaque donnée est un enseignement, une règle implicite, un biais potentiel. Leur fiabilité détermine si ces enseignements seront pertinents ou trompeurs.
Pensez-y comme à l’éducation d’un enfant. Si vous n’enseignez à un enfant que des mathématiques, jamais de littérature, d’histoire ou d’art, vous n’aurez pas un génie des mathématiques. Vous aurez un être humain incomplet, avec une vision du monde déformée. La rigueur des données est analogue à la qualité de l’éducation : elle détermine la capacité à généraliser et à s’adapter.
Votre IA est cet enfant. Vos données sont son éducation. C’est ce qui détermine si votre enfant deviendra un expert équilibré ou un spécialiste aux angles morts dangereux. L’avantage concurrentiel se construit sur cette distinction fondamentale.
🧠 Mon analyse personnelle : Les 3 vérités brutales sur les données et l’IA
Chez Athrar, j’accompagne quotidiennement des entreprises dans la construction de leur avantage concurrentiel. Je constate que trois vérités fondamentales sont systématiquement ignorées ou sous-estimées.
Vérité n°1 : La donnée absente est plus dangereuse que la donnée fausse
Je travaillais avec un fonds en 2021 qui sélectionnait les altcoins selon une IA entraînée sur les altcoins qui avaient survécu jusqu’en 2021. Évidemment. Les tokens morts, abandonnés, scams – ils n’étaient plus dans les bases de données. Leur IA apprenait donc sur un échantillon parfaitement biaisé : les gagnants.
Le résultat ? Une surexposition systématique aux risques. Le modèle ne « voyait » pas les patterns d’échec, car ils avaient été effacés de l’histoire. La fiabilité des données passait par la reconstitution de ces données manquantes, un travail fastidieux mais essentiel.
Notre solution : Nous avons créé ce que nous appelons la « nécropole des données ». Une base séparée, maintenue manuellement, de tous les tokens morts, scams et échecs que nous avons pu documenter. C’est coûteux. C’est fastidieux. Mais c’est la seule façon d’avoir une vision complète du risque réel. C’est notre avantage concurrentiel, construit sur une rigueur irréprochable.
Vérité n°2 : Le volume des données est un piège
Nous vivons dans le culte du volume. « Notre IA a ingéré 50 To de données ! » C’est censé impressionner. En réalité, cela devrait inquiéter.
Chaque donnée supplémentaire a un coût qui affecte la pertinence de l’ensemble :
- Coût de stockage
- Coût de calcul
- Coût de qualité (plus vous avez de données, plus il est difficile de maintenir une homogénéité)
- Coût cognitif (plus votre équipe doit gérer de sources, moins elle en comprend chaque nuance)
La loi des rendements décroissants s’applique férocement. Les premiers gigaoctets de données propres apportent 80% de la valeur. Les téraoctets suivants apportent souvent du bruit, des doublons, des artefacts qui dégradent l’ensemble. L’avantage concurrentiel se construit sur la pertinence, pas sur le volume.
Vérité n°3 : Le traitement des données blockchain est un acte d’interprétation
Le traitement des données blockchain n’est pas une fonction Python à exécuter. C’est un acte d’interprétation qui détermine la pertinence des résultats.
Une transaction on-chain n’est pas qu’un transfert de A à B. C’est un témoignage. Elle témoigne d’une intention, d’une émotion, d’une stratégie. Mais sans contexte, ce témoignage est muet. La gestion des données dans la DeFi exige de donner du sens à ces transactions.
Pendant longtemps, nous analysions les flux de stablecoins vers les exchanges comme un indicateur d’intention d’achat. Logique, non ? Sauf que nous avons découvert (à nos dépens) qu’une partie significative de ces transferts venait de market makers faisant de l’arbitrage entre CEX, pas de retail prêt à acheter.
La donnée brute disait : « Transfert USDT vers Binance ». La réalité disait : « Opération technique sans conviction marché ». Le traitement des données blockchain doit donc enrichir les données de métadonnées contextuelles pour améliorer leur pertinence.
🔬 Les 3 catastrophes que j’ai vues de mes propres yeux

Catastrophe n°1 : L’oracle qui nettoie trop bien
Un protocole DeFi utilisait un oracle de prix qui appliquait une moyenne mobile sur 7 sources, éliminant les « outliers ». Propre. Élégant. Et fatal.
Quand un acteur a manipulé le prix sur 3 petits DEX pendant 15 minutes, l’oracle a ignoré ces « anomalies ». Mais le marché réel, lui, s’était arbitragé sur ces prix. La valeur du collatéral était fictive. Exploit. Drainage. Fin.
La leçon : Parfois, le « bruit » est le signal le plus important. Une gestion rigoureuse des données dans la DeFi aurait dû conserver ces anomalies pour préserver la fiabilité de l’ensemble.
Catastrophe n°2 : L’IA qui n’avait jamais vu la peur
Un fonds quantitatif avait entraîné son modèle sur 2020-2023. Une période globalement haussière. Leur Sharpe Ratio en backtest ? Spectaculaire.
Leur première vraie période de stress en 2024 ? Catastrophique. Le modèle n’avait jamais « vu » de panique réelle. Il continuait d’acheter les dips comme en 2021. Sauf que cette fois, le dip ne remontait pas.
La leçon : Si vos données ne contiennent pas d’échecs, votre IA ne peut pas apprendre à les éviter. La fiabilité des données exige une représentation de tous les régimes de marché.
Catastrophe n°3 : La source premium qui cache l’essentiel
Nous avions souscrit à un flux de données « premium » déjà « nettoyé et agrégé ». Confiants, nous l’avons injecté directement.
Les signaux étaient étranges. En creusant, découverte : leur « nettoyage » supprimait toutes les transactions de moins de 10k$, considérées comme du « bruit ». Or, en crypto, l’activité des petits portefeuilles est souvent un indicateur avancé de sentiment.
La leçon : Ne jamais déléguer votre jugement sur ce qui est « bruit » et ce qui est « signal ». Le traitement des données blockchain doit être maîtrisé en interne pour garantir leur pertinence.
⚖️ Les nuances : Quand la qualité des données en IA n’est pas le seul facteur
Il est crucial de remettre en perspective le rôle de la qualité des données en IA. Ce n’est pas le seul facteur de succès des données et intelligence artificielle.
1. L’algorithme compte aussi
Un algorithme mal adapté au problème ne sera pas sauvé par des données parfaites. La qualité des données en IA est nécessaire, mais pas suffisante pour garantir un avantage concurrentiel données.
2. Le contexte métier est essentiel
La qualité des données en IA dépend du problème à résoudre. Des données parfaites pour un cas d’usage peuvent être inadaptées pour un autre. Les données et intelligence artificielle doivent être alignées sur les objectifs métier.
3. L’infrastructure technique est un prérequis
Sans une infrastructure capable de collecter, stocker et traiter les données, la qualité des données en IA reste théorique. La gestion données DeFi nécessite des outils spécifiques.
4. La gouvernance est indispensable
La qualité des données en IA ne se décrète pas. Elle s’installe dans une gouvernance rigoureuse, comme le cadre DAMA DMBOK, qui établit les principes fondamentaux de la gestion des données.
5. Le facteur humain est déterminant
La qualité des données en IA dépend de la culture d’entreprise. Une équipe qui ne valorise pas la rigueur des données ne produira jamais un avantage concurrentiel données durable.
🏆 Mon verdict : L’avantage concurrentiel données comme levier stratégique
Je vais vous dire un secret : après avoir conseillé des dizaines de projets, des fonds d’investissement aux protocoles DeFi, j’ai identifié le seul facteur qui prédit systématiquement le succès à long terme des données et intelligence artificielle.
Ce n’est pas la complexité de l’algorithme. Ce n’est pas le volume des données. Ce n’est même pas la qualité technique de l’équipe.
C’est l’humilité face aux données.
L’humilité de reconnaître que :
- Nos données ont toujours des angles morts
- Nos modèles ont toujours des biais
- Notre compréhension est toujours partielle
- La confiance doit être gagnée, jamais présumée
Les projets qui réussissent sont ceux qui intègrent cette humilité dans leur ADN. Qui consacrent autant de temps à comprendre leurs données qu’à construire leurs modèles. Qui célèbrent la découverte d’une erreur dans leurs données comme une victoire, pas un échec. C’est ainsi que se construit un véritable avantage concurrentiel données.
Données et intelligence artificielle ne sont pas une relation de maître à serviteur. C’est un partenariat. Vos données ne sont pas votre domestique. Elles sont votre conseiller le plus critique, le plus franc, et parfois le plus brutal. La qualité des données en IA est le ciment de ce partenariat.
L’écouter demande du courage. L’entendre demande de l’humilité. Agir en conséquence demande de la discipline.
Mais c’est le seul chemin vers un avantage concurrentiel données qui ne s’érode pas avec le temps, qui ne se copie pas avec un fork, qui ne se dilue pas avec la concurrence. Dans un monde obsédé par la vitesse, la sophistication et la scale, l’avantage ultime revient paradoxalement à ceux qui ont le courage d’être lents, rigoureux et profonds sur la qualité des données en IA.

Pour Aller Plus Loin :
- Pour comprendre les risques des mauvaises données, découvrez mon analyse sur les limites réelles de l’IA , un complément indispensable à votre stratégie sur les données et intelligence artificielle.
- Maîtrisez les fondamentaux avec notre article sur les 7 piliers de l’IA moderne pour solidifier vos bases sur la qualité des données en IA.
- Explorez mon analyse sur l’éthique et la sécurité de l’IA pour comprendre les enjeux de gouvernance des données et intelligence artificielle.
- Pour une perspective globale sur l’impact économique, consultez mon article sur l’infrastructure IA , un secteur en pleine explosion qui dépend de la qualité des données en IA.
- Consultez le cadre de référence de l’OCDE sur l’intelligence artificielle pour aligner vos projets avec les standards internationaux.
- Pour des données complémentaires sur la qualité des données en IA, le rapport State of AI 2026 est une ressource incontournable.
❓ FAQ : Vos questions sur les données et intelligence artificielle
Quel est le lien entre données et intelligence artificielle ?
Les données et intelligence artificielle sont indissociables : les données sont la matière première qui détermine la performance des modèles. Sans qualité des données en IA, les modèles produisent des résultats biaisés ou incohérents. La fiabilité des données est le facteur numéro 1 de réussite des projets.
Pourquoi 85% des projets IA échouent-ils ?
Selon Gartner (2026), 85% des projets d’IA échouent à cause de problèmes de qualité des données en IA : biais, qualité insuffisante, volume inadapté ou absence de données représentatives. Les données et intelligence artificielle ne font pas bon ménage sans une rigueur absolue dans la préparation et le prétraitement données blockchain.
Comment améliorer la qualité des données en IA ?
L’amélioration de la qualité des données en IA passe par 7 piliers : la chasse aux biais, le traitement intelligent, la traçabilité absolue, l’enrichissement stratégique, les tests adversariaux, la documentation vivante et la culture de la qualité. Chaque étape contribue à renforcer l’avantage concurrentiel données.
Qu’est-ce que le prétraitement données blockchain ?
Le prétraitement données blockchain est l’étape cruciale de nettoyage et d’enrichissement des données on-chain avant leur utilisation dans des modèles d’IA. Il inclut la validation des transactions, l’enrichissement contextuel et la correction des biais. Une qualité des données en IA optimale passe par un prétraitement données blockchain rigoureux.
Comment la gestion données DeFi se distingue-t-elle ?
La gestion données DeFi est spécifique car elle doit traiter des données hautement volatiles, des oracles de prix multiples, des attaques potentielles et des manipulations de marché. Elle exige des protocoles de validation rigoureux et une diversification des sources pour garantir la qualité des données en IA.
Qu’est-ce qu’un avantage concurrentiel données ?
Un avantage concurrentiel données est un atout durable qu’une entreprise construit grâce à une qualité des données en IA supérieure à ses concurrents. Il se traduit par des modèles plus performants, des décisions plus éclairées et une capacité à s’adapter plus rapidement aux changements du marché.
Athrar — Je suis analyste et stratège en transformation digitale. J’accompagne les entreprises dans l’adoption de l’intelligence artificielle depuis 2023, avec un focus particulier sur la qualité des données en IA et la construction d’un avantage concurrentiel données. Retrouvez-moi sur LinkedIn pour plus d’analyses sur les données et intelligence artificielle. Mes propos n’engagent que moi et ne sont pas des conseils en investissement.
1 réflexion au sujet de « Données et Intelligence Artificielle : 3 Vérités CHOC sur l’Échec CATASTROPHIQUE des Projets IA en 2026 »
Les commentaires sont fermés.