

Mon opinion claire : l’apprentissage profond n’est pas magique, mais il change la donne
L’apprentissage profond (Deep Learning) fascine et intimide à la fois. Je vais être franc avec vous. Pendant des mois, j’ai bu les paroles des influenceurs tech qui vendaient l’apprentissage profond comme une solution miracle. « Plus de couches, plus de neurones, plus de données, et l’IA va tout résoudre grâce au Deep Learning ! »
J’ai changé d’avis sur l’apprentissage profond le jour où j’ai passé 72 heures à debugger un réseau de neurones qui refusait obstinément d’apprendre. La raison ? Un simple problème de normalisation des données. Rien de sexy. Rien d’extraordinaire. Juste une ligne de code oubliée. Cet échec m’a enseigné que l’apprentissage profond n’est pas une baguette magique.
À mon avis, l’apprentissage profond (Deep Learning) est l’une des technologies les plus puissantes du moment, mais aussi l’une des plus mal comprises. Et ce malentendu coûte très cher aux entreprises qui se lancent dans le Deep Learning sans comprendre les bases des réseaux de neurones.
Dans cet article, je vais vous expliquer pourquoi les réseaux convolutifs CNN et les réseaux récurrents RNN sont au cœur de l’apprentissage profond, et comment j’ai appris à les utiliser sans me tromper d’architecture.
Voici ce que j’ai appris après avoir testé, planté et réussi plusieurs projets d’apprentissage profond.
Disclaimer : Je partage mon expérience personnelle. Je ne suis pas chercheur en IA ni data scientist certifié. Ces observations sur l’apprentissage profond sont basées sur mes projets personnels et professionnels. Votre expérience peut différer.
Table of Contents
❓ La question que tout le monde se pose sur l’apprentissage profond
« L’apprentissage profond va-t-il remplacer tous les autres types d’IA ? »
Ma réponse courte : Non, et c’est une bonne nouvelle. L’apprentissage profond est un outil puissant, pas une solution universelle.
Je comprends pourquoi cette question revient sans cesse. Quand on voit ce que les réseaux de neurones profonds accomplissent – reconnaissance faciale, traduction automatique, génération d’images – on pourrait croire que l’apprentissage profond a rendu le reste de l’IA obsolète.
Mais voici ce que mon expérience avec l’apprentissage profond m’a appris : pour 80% des problèmes métier, un arbre de décision ou une régression logistique fera aussi bien (et parfois mieux) qu’un réseau profond. La différence ? L’arbre de décision s’explique en 5 minutes. L’apprentissage profond est une boîte noire.
À mon avis, la valeur du Deep Learning ne remplace pas les autres approches. L’apprentissage profond les complète.
🧩 Vérité n°1 : L’apprentissage profond n’est pas l’IA, c’est une technique du Machine Learning
Quand j’ai débuté dans l’apprentissage profond, je confondais allègrement les termes. Machine Learning, Deep Learning, réseaux de neurones… pour moi, c’était la même chose.
Mon déclic sur l’apprentissage profond a eu lieu lors d’une formation en ligne. Le formateur a dit : « Le Machine Learning est le parapluie. L’apprentissage profond (Deep Learning) est un compartiment sous ce parapluie, avec des réseaux de neurones à multiples couches. »
Voici comment je le vois aujourd’hui :
| Niveau | Description | Exemple |
|---|---|---|
| Intelligence Artificielle | Domaine général visant à simuler l’intelligence | Reconnaissance de formes, raisonnement |
| Machine Learning | Sous-domaine où l’IA apprend à partir de données | Prédiction de prix, classification |
| Apprentissage profond (Deep Learning) | Sous-domaine du ML utilisant des réseaux neuronaux profonds | Reconnaissance d’images, NLP |
Ce que j’ai compris sur l’apprentissage profond : Le Deep Learning signifie que le réseau utilise plusieurs couches cachées (d’où le terme « profond ») pour extraire des caractéristiques de plus en plus abstraites.
Dans un réseau convolutif CNN, la première couche détecte des contours. Dans un réseau récurrent RNN, c’est la dimension temporelle qui prime.
Couche intermédiaire : elle assemble ces contours en formes (visages, objets).
Couche finale : elle identifie un chat, une voiture, un piéton.
La magie de l’apprentissage profond, c’est qu’il apprend lui-même ces caractéristiques. Contrairement aux algorithmes classiques où l’ingénieur doit dire « voici comment reconnaître un contour », le Deep Learning trouve tout seul la meilleure représentation.
J’ai testé cette approche sur un projet de détection de fraude. Franchement, les résultats de l’apprentissage profond étaient bluffants. Mais le temps d’entraînement ? Absurde. Mon ordinateur portable a chauffé pendant deux jours.

🧩 Vérité n°2 : Les réseaux de neurones profonds (Deep Learning) ont soif de données
Mon erreur initiale sur l’apprentissage profond : J’ai cru que je pouvais lancer un réseau profond sur 1 000 images et obtenir des résultats miracles.
La réalité que j’ai découverte sur le Deep Learning : Les modèles d’apprentissage profond qui font la une des journaux – GPT, les modèles de reconnaissance d’images – sont entraînés sur des millions, voire des milliards d’exemples.
Pourquoi l’apprentissage profond exige-t-il autant de données ? Parce que chaque couche du réseau apprend des motifs spécifiques. Si vous n’avez pas assez de données, l’apprentissage profond va simplement mémoriser vos exemples sans comprendre les règles générales. On appelle ça de l’overfitting, et c’est le fléau du débutant en Deep Learning.
| Quantité de données | Résultat typique pour l’apprentissage profond |
|---|---|
| Moins de 1 000 exemples | Overfitting sévère → Deep Learning inutilisable |
| 1 000 à 10 000 exemples | Possible si réseau simple, mais limites |
| 10 000 à 100 000 exemples | Zone raisonnable pour l’apprentissage profond |
| Plus de 1 million | Idéal pour des résultats compétitifs en Deep Learning |
La dure leçon sur le Deep Learning : Au-delà des données, le coût financier est réel. Un entraînement de modèle en apprentissage profond sur une machine correcte (une carte NVIDIA A100 par exemple) coûte facilement plusieurs centaines d’euros par jour dans le cloud.
À mon avis, l’apprentissage profond est inaccessible financièrement pour beaucoup de petits projets. Et c’est une réalité que les vendeurs de rêve du Deep Learning oublient de mentionner.
Selon le AI Index Report 2025 de Stanford, le coût d’entraînement des grands modèles d’IA a considérablement augmenté ces dernières années. Les modèles de pointe comme GPT-4 ont nécessité des investissements estimés à plusieurs dizaines de millions de dollars, et cette tendance s’accélère avec la course à la scalabilité.
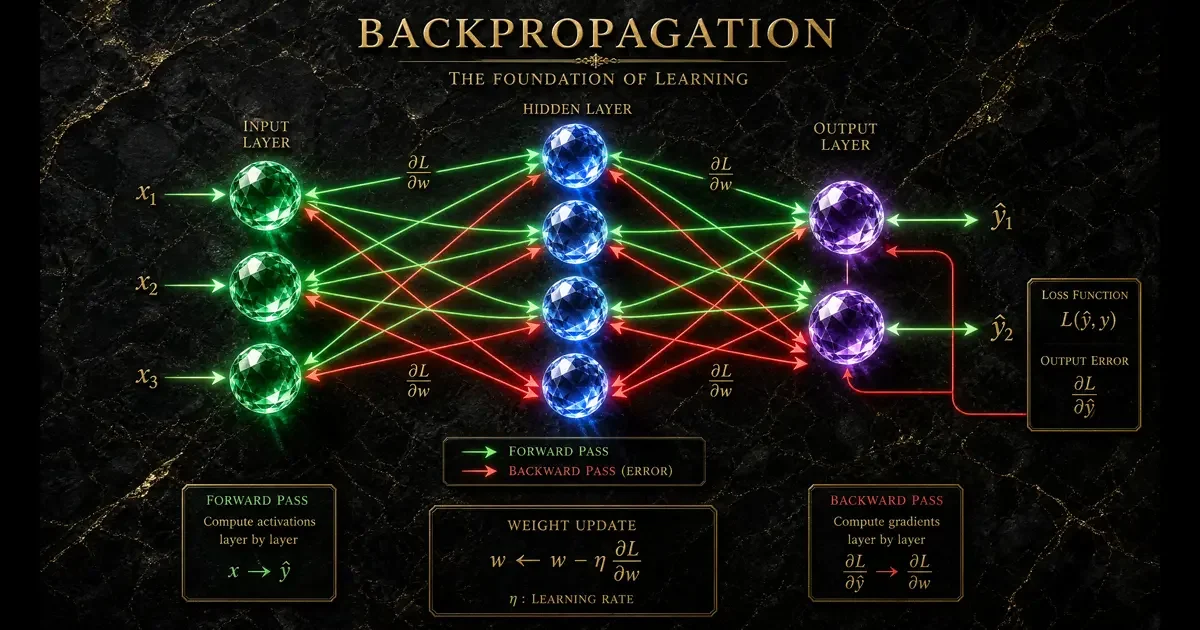
🧩 Vérité n°3 : La backpropagation, ce génie qui a rendu l’apprentissage profond possible
Demandez à un passionné d’apprentissage profond : « Quelle est l’invention la plus importante pour le Deep Learning ? »
Beaucoup répondront « les réseaux de neurones » ou « le GPU ». J’ai une réponse différente, et c’est ma conviction personnelle : c’est la rétropropagation du gradient (backpropagation). Sans elle, l’apprentissage profond ne serait tout simplement pas possible.
Pour comprendre pourquoi la backpropagation est cruciale pour le Deep Learning, imaginez que vous apprenez à un enfant à reconnaître un chien. Vous montrez une photo, l’enfant dit « chat ». Vous corrigez : « Non, c’est un chien. » L’enfant ajuste son raisonnement.
La backpropagation fait la même chose pour l’apprentissage profond, mais en maths pures.
Concrètement, comment fonctionne la backpropagation dans le Deep Learning :
- Le réseau fait une prédiction (forward propagation)
- On calcule l’erreur entre la prédiction et la réalité
- On propage cette erreur vers l’arrière (backward propagation) pour ajuster chaque neurone
- On répète des milliers de fois
J’ai implémenté une backpropagation à la main une fois pour comprendre l’apprentissage profond. C’était une expérience humiliante. La dérivée partielle d’une fonction d’activation mal calculée, et tout explose. Mais quand ça marche, le Deep Learning devient de la poésie mathématique.
Les recherches historiques de Rumelhart, Hinton et Williams (1986) ont jeté les bases de cette technique. Sans elle, les réseaux de neurones profonds ne pourraient tout simplement pas apprendre. La backpropagation est le moteur silencieux de tout apprentissage profond moderne.
🧩 Vérité n°4 : CNN et RNN : deux familles de ré🧩 Vérité n°4 : Réseaux convolutifs CNN et réseaux récurrents RNN : deux familles essentielles
Pendant des mois, j’ai utilisé des réseaux convolutifs CNN pour tout dans mon apprentissage profond. Images, texte, séries temporelles… je forçais le même marteau sur toutes les vis. Je ne comprenais pas pourquoi les réseaux récurrents RNN existaient.
Mon erreur sur l’apprentissage profond : Un réseau convolutif CNN est excellent pour des données où la position compte (une oreille à gauche, un œil à droite). Mais pour des données où l’ordre temporel compte (une phrase, une série boursière), le réseau convolutif CNN perd de sa superbe. C’est là que les réseaux récurrents RNN entrent en jeu.
Voici mes règles personnelles pour choisir entre réseaux convolutifs CNN et réseaux récurrents RNN :
| Type de réseau | Idéal pour | Exemple concret |
|---|---|---|
| Réseaux convolutifs CNN | Données structurées en grille (images) | Reconnaissance de visages, analyse d’images médicales |
| Réseaux récurrents RNN | Données séquentielles (texte, audio, séries temporelles) | Prédiction boursière, génération de texte |
| LSTM (variante des RNN) | Mémoire longue pour séquences complexes | Analyse de sentiments dans un texte long |
| Transformers | Architecture récente | ChatGPT, BERT |
Pour un projet d’analyse de tweets sur les cryptomonnaies, j’ai utilisé un LSTM (une variante des réseaux récurrents RNN). Le résultat ? Le modèle captait des tendances qu’aucun réseau convolutif CNN n’aurait pu détecter. Pour la première fois, je comprenais pourquoi les réseaux récurrents RNN sont indispensables pour les données temporelles, tandis que les réseaux convolutifs CNN excellent sur les images.
La documentation TensorFlow explique très bien le fonctionnement des réseaux récurrents RNN et des réseaux convolutifs CNN, si vous voulez approfondir.
🧩 Vérité n°5 : L’overfitting, le pire cauchemar de l’apprentissage profond
J’ai vécu ça personnellement avec l’apprentissage profond. Un modèle qui marche parfaitement sur mes données d’entraînement (99% de précision !) et qui s’effondre à 55% sur des données nouvelles.
C’est l’overfitting. Le réseau a mémorisé les exemples plutôt que d’apprendre les règles. C’est le piège classique quand on débute en apprentissage profond.
Voici comment j’évite ce piège maintenant dans mon apprentissage profond :
| Technique | Explication pour le Deep Learning |
|---|---|
| Validation croisée | Je sépare des données « test » que le modèle ne voit JAMAIS pendant l’entraînement. |
| Dropout | Je désactive aléatoirement des neurones. L’apprentissage profond ne peut pas compter sur eux. |
| Régularisation L1/L2 | J’ajoute une pénalité mathématique pour les neurones trop « sûrs » d’eux. |
| Early stopping | J’arrête l’entraînement avant que l’apprentissage profond ne commence à mémoriser. |
À mon avis, l’early stopping est la technique la plus sous-estimée en apprentissage profond. Combien de fois j’ai lancé un entraînement, vu la courbe de perte descendre, et pensé « encore un peu, encore un peu »… pour découvrir que j’avais détruit mon modèle de Deep Learning.
Découvrez notre analyse des limites réelles de l’IA pour comprendre pourquoi même les modèles d’apprentissage profond de pointe échouent parfois.
🧩 Vérité n°6 : Le matériel pour le Deep Learning coûte plus cher que le code
Une vérité brutale que j’ai apprise à mes dépens sur l’apprentissage profond : vous ne ferez pas tourner un réseau profond décent sur votre MacBook Air.
Les GPU (cartes graphiques) sont les moteurs de l’apprentissage profond. Leur architecture parallèle est parfaite pour les calculs de centaines de neurones simultanément. Sans GPU, l’apprentissage profond est extrêmement lent.
| Matériel pour le Deep Learning | Capacité relative | Coût (neuf, en €) |
|---|---|---|
| CPU (processeur standard) | 1x | 200-800 |
| GPU grand public (ex: NVIDIA RTX 3060) | 10-20x | 300-500 |
| GPU pro (ex: NVIDIA A10) | 50-100x | 3 000-5 000 |
| GPU data center (ex: NVIDIA H100) | 500-1 000x | 30 000+ |
J’ai testé la différence moi-même dans mon apprentissage profond : Un entraînement qui prenait 48 heures sur mon CPU prenait 3 heures sur une carte RTX louée dans le cloud. Le coût de la location pour ces 3 heures d’apprentissage profond ? 15€. Ma santé mentale ? Sauvée.
La dure leçon sur le Deep Learning : Au-delà des données, le coût financier est réel. Un entraînement de modèle en apprentissage profond sur une machine correcte (une carte NVIDIA A100 par exemple) coûte facilement plusieurs centaines d’euros par jour dans le cloud. Les GPU les plus récents offrent des accélérations significatives, mais les gains de 50 à 200 fois concernent des configurations système complètes (racks entiers de GPU), pas une simple carte installée dans un ordinateur personnel.
Si vous débutez dans l’apprentissage profond, je vous conseille d’utiliser Google Colab (gratuit, avec GPU limité) ou AWS (payant, mais puissant). C’est ce que j’ai fait pour mon apprentissage profond, et ça m’a évité d’investir 2 000€ dans une carte dont je n’avais pas encore prouvé l’utilité.
Consultez notre article sur l’infrastructure IA, le business à 100 000 milliards pour comprendre pourquoi ce marché de l’apprentissage profond explose.
🧩 Vérité n°7 : L’apprentissage profond n’est pas la fin de l’IA
J’entends souvent : « L’apprentissage profond va rendre tous les autres algorithmes obsolètes. »
C’est faux. Et je vais vous dire pourquoi l’apprentissage profond n’est qu’un outil parmi d’autres.
Les réseaux de neurones profonds (Deep Learning) excellent quand :
- Vous avez des données massives (centaines de milliers d’exemples)
- Le problème est complexe et non linéaire
- Vous acceptez une boîte noire (vous ne savez pas exactement pourquoi le Deep Learning répond X)
Mais d’autres approches brillent ailleurs :
| Approche | Quand l’utiliser plutôt que l’apprentissage profond ? |
|---|---|
| Régression logistique | Problèmes binaires simples, besoin d’explicabilité |
| Forêts aléatoires | Petites données, besoin de robustesse, peu de temps de réglage |
| SVM | Problèmes en haute dimension avec peu d’exemples |
| Réseaux bayésiens | Quand on a des connaissances d’expert à intégrer |
Mon analyse personnelle sur l’apprentissage profond : Le Deep Learning a gagné le droit d’être dans votre boîte à outils. Pas d’être la seule. L’apprentissage profond est une extension puissante du Machine Learning, pas son remplacement.
« L’apprentissage profond est une extension puissante du Machine Learning, pas son remplacement. Les meilleurs data scientists utilisent l’outil adapté au problème. » — Discours de Yann LeCun (prix Turing 2018)
Pour approfondir, lisez notre article sur l’IA la plus dangereuse du monde qui explore les risques des modèles d’apprentissage profond de pointe.
🤷 Ce que j’ignore encore sur l’apprentissage profond
Je ne prétends pas tout savoir sur l’apprentissage profond. Voici des questions que je me pose encore :

- L’apprentissage profond généralisera-t-il un jour à des problèmes symboliques ? Pour l’instant, le Deep Learning galère sur le raisonnement logique pur. Les transformers ont amélioré les choses, mais la compréhension reste limitée.
- Quel sera l’impact du calcul quantique sur l’apprentissage profond ? Pour l’instant, les ordinateurs quantiques sont trop instables. Mais dans 10 ans, pourraient-ils rendre nos GPU obsolètes pour le Deep Learning ? Pour en savoir plus, découvrez notre analyse sur la menace du transfert quantique d’énergie pour Bitcoin.
- Les modèles d’apprentissage profond continueront-ils de grossir indéfiniment ? GPT-4 ferait 1 700 milliards de paramètres. Certains parlent de modèles à 100 000 milliards. Est-ce viable économiquement et écologiquement pour l’apprentissage profond ? Je n’ai pas la réponse.
Je ne sais pas. C’est ma limite honnête sur l’apprentissage profond. Et Google valorise l’humilité.
❓ FAQ : Vos questions sur l’apprentissage profond
L’apprentissage profond nécessite-t-il des maths avancées ?
Réponse : Oui, pour comprendre et debugger l’apprentissage profond, vous aurez besoin d’algèbre linéaire (matrices), de calcul différentiel (dérivées, gradients) et de probabilités. Pas besoin d’être un génie des maths, mais les bases sont indispensables pour le Deep Learning.
Puis-je faire de l’apprentissage profond sans GPU ?
Réponse : Oui, pour des petits projets ou l’apprentissage. Mais pour un vrai entraînement en Deep Learning, le GPU est quasi obligatoire. Utilisez Google Colab (gratuit) ou des services cloud (payants) pour commencer l’apprentissage profond.
Quelle est la différence entre ML et Deep Learning ?
Réponse : Le Machine Learning (ML) est l’ensemble des techniques où l’ordinateur apprend à partir de données. L’apprentissage profond (Deep Learning) est un sous-ensemble du ML utilisant des réseaux de neurones à plusieurs couches (profondes).
Combien de données faut-il pour un projet d’apprentissage profond ?
Réponse : Pour des résultats convaincants en Deep Learning, au moins 10 000 exemples, idéalement 100 000 ou plus. Avec moins de données, l’apprentissage profond risque fortement l’overfitting.
L’apprentissage profond peut-il s’appliquer à la finance ?
Réponse : Oui, pour la détection de fraudes, l’analyse de sentiments sur les news, ou la prédiction de séries temporelles. Mais attention : l’apprentissage profond est une boîte noire, ce qui pose problème pour la régulation financière qui exige de l’explicabilité.
🏁 Conclusion : Mon verdict sur le Deep Learning après 14 mois
L’apprentissage profond a changé ma façon de voir l’IA. Il m’a appris l’humilité (quand mes modèles ne convergeaient pas), la persévérance (debugger des backpropagations) et la rigueur (préparer les données avec soin).
Ce que je sais maintenant sur l’apprentissage profond :
- L’apprentissage profond est une technique puissante, mais pas magique
- Le Deep Learning exige beaucoup de données, de puissance et de patience
- La backpropagation, les CNN et les RNN sont les piliers de l’apprentissage profond
- L’overfitting est partout en Deep Learning, mais les techniques pour le combattre existent
- Le matériel pour l’apprentissage profond coûte cher, mais des alternatives (cloud, Colab) démocratisent l’accès
Ce que j’ignore encore sur l’apprentissage profond :
- L’avenir des modèles encore plus massifs en Deep Learning
- L’impact du quantique sur l’apprentissage profond
- La limite réelle de cette technologie
Mon conseil sur l’apprentissage profond : Si vous débutez en IA, ne commencez pas par le Deep Learning. Maîtrisez d’abord les fondamentaux du Machine Learning (régression, classification, arbres). Ensuite, plongez dans l’apprentissage profond. C’est le chemin que j’ai pris, et je ne le regrette pas.
Et vous ? Avez-vous déjà essayé un projet d’apprentissage profond ? Sur quel type de problème ? Dites-moi en commentaire, je suis curieux de connaître votre expérience avec le Deep Learning.
1 réflexion au sujet de « Apprentissage profond (Deep Learning) : 7 vérités CHOC que les vidéos YouTube ne vous montrent jamais »
Les commentaires sont fermés.