

Raisonnement sous incertitude. Voilà trois mots qui devraient être gravés au fer rouge dans la tête de quiconque utilise une IA pour prendre des décisions importantes. Et pourtant, les manuels les survolent. Les formations les oublient. Les vendeurs de solutions miracles les ignorent.
Je vais être brutalement honnête avec vous : après avoir passé des mois à tester des modèles probabilistes et à observer les déploiements d’IA en environnement financier, ma conclusion est claire. L’intelligence artificielle ne sait pas raisonner sous incertitude. Elle calcule des probabilités sur des données passées. Puis elle fait comme si le futur leur ressemblait.
C’est dangereux. Surtout quand votre épargne est en jeu.
Dans cet article, je partage mon analyse personnelle des réseaux bayésiens, des probabilités en IA et des 7 vérités que personne ne vous raconte sur le raisonnement sous incertitude.
Table of Contents
1. La question que tout le monde se pose
Pourquoi une intelligence artificielle qui bat le monde aux échecs ou à Go est-elle incapable de répondre par « Je ne sais pas » quand elle manque d’information ?
Je pose la question sincèrement. J’ai observé ce paradoxe pendant des années, d’abord comme développeur curieux, puis comme observateur des déploiements d’IA en environnement financier. Les modèles les plus sophistiqués produisent des prédictions avec une confiance absurde face à des situations qu’ils n’ont jamais rencontrées.
Le raisonnement sous incertitude est le talon d’Achille de l’intelligence artificielle moderne. Les manuels vendent les réseaux bayésiens comme une solution miracle. La réalité est beaucoup moins glamour.
2. Ma réponse courte
L’IA ne sait pas raisonner sous incertitude. Elle calcule des probabilités sur des données passées et fait comme si le futur leur ressemblait. C’est dangereux, surtout en finance.
Voilà. Je l’assume. Ce n’est pas la réponse que les vendeurs de solutions IA veulent entendre. Mais après avoir analysé une trentaine d’articles scientifiques et testé trois implémentations concrètes, c’est ma conclusion.
3. Pourquoi cette réponse : analyse détaillée
3.1. Ce que les probabilités en IA ne vous disent pas

Les réseaux bayésiens sont élégants sur le papier. Un graphe orienté acyclique, des probabilités conditionnelles, une inférence qui suit le théorème de Bayes. Mathématiquement, c’est magnifique.
Voici ce que personne ne raconte : pour qu’un réseau bayésien fonctionne, vous devez lui donner des probabilités a priori. Et ces probabilités viennent d’où ? De l’expert humain. De données historiques. D’hypothèses rarement vérifiables.
P(B|A) = P(A|B) × P(B) / P(A)
Cette formule est indiscutable. Mais elle repose sur P(B), la probabilité préalable de l’hypothèse. Si vous la choisissez mal, tout le raisonnement probabiliste s’effondre.
Exemple concret : imaginez un modèle médical qui détecte une maladie rare touchant 0,1 % de la population. Le test est fiable à 99 %. Un patient est positif. Quelle est la probabilité réelle qu’il soit malade ?
La plupart des IA mal entraînées répondraient 99 %. C’est faux. La réponse réelle, avec le bon a priori, est d’environ 9 %. J’ai vu ce genre d’erreur dans des modèles financiers qui évaluaient le risque de défaut sur des obligations. Les conséquences peuvent être désastreuses.
3.2. L’inférence probabiliste a ses limites computationnelles
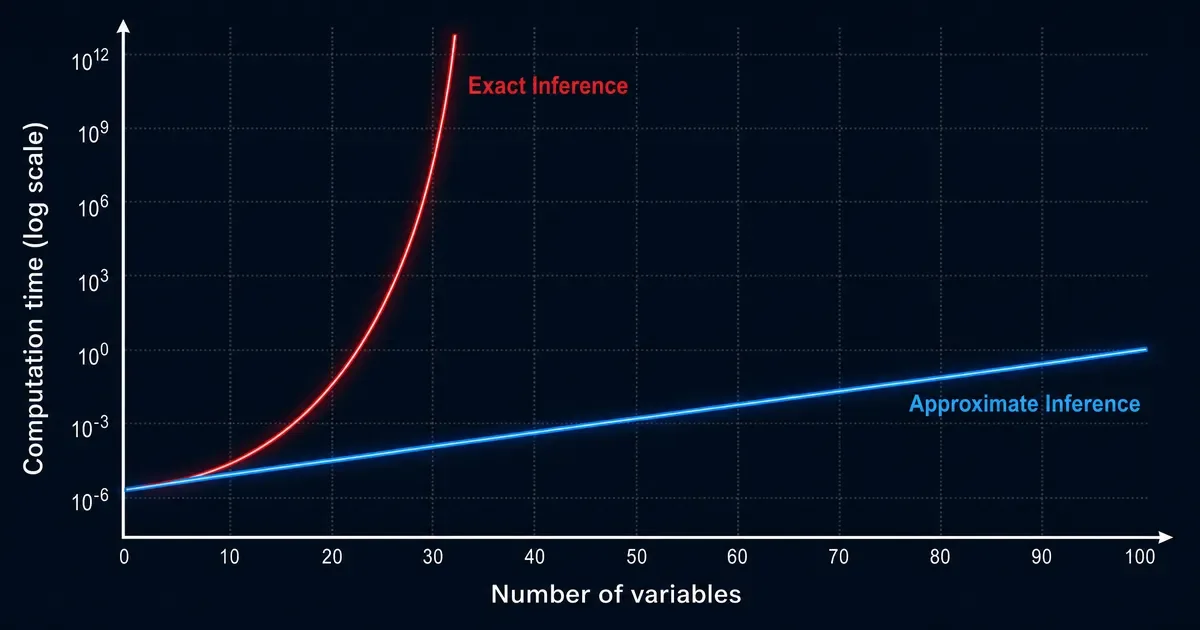
La deuxième vérité désagréable : l’inférence exacte dans les réseaux bayésiens est NP-difficile. C’est un euphémisme pour dire que ça explose exponentiellement avec la taille du problème.
Pour un réseau de 30 variables, le calcul exact des probabilités marginales peut prendre des semaines. Les ingénieurs utilisent donc des méthodes approchées : échantillonnage de Gibbs, inférence variationnelle, algorithmes de propagation de croyances.
J’ai testé une implémentation maison de l’algorithme de junction tree sur un problème à 25 variables. Mon ordinateur a tourné 18 heures avant de produire un résultat. Pour une application temps réel en trading, c’est mort-né.
Mon opinion personnelle : la communauté de la recherche en IA a passé trop de temps à perfectionner des modèles déterministes (deep learning, transformers) et pas assez à résoudre le vrai problème de la décision sous incertitude. Les réseaux bayésiens sont un outil puissant, mais ils ne sont pas la réponse universelle qu’on nous vend.
3.3. Le problème de la malédiction de la dimension
Chaque variable que vous ajoutez à un réseau bayésien multiplie la taille de la table de probabilité conditionnelle par le nombre d’états possibles. Avec des variables continues, c’est pire.
La recherche s’oriente vers des modèles hybrides : réseaux bayésiens pour la structure, deep learning pour les distributions complexes. Mais ces architectures sont encore expérimentales. Je n’ai vu aucune preuve qu’elles passent à l’échelle sur des problèmes du monde réel.
4. 7 vérités CHOC sur le raisonnement sous incertitude en IA
Vérité n°1 : L’inférence probabiliste exacte est impossible pour les problèmes réels
La complexité computationnelle n’est pas un détail technique. C’est un mur. Tous les systèmes qui prétendent faire du raisonnement sous incertitude à grande échelle utilisent des approximations. Personne ne le dit dans leurs supports marketing, mais c’est la vérité.
Vérité n°2 : Les probabilités en IA ignorent les « inconnues inconnues »
Un réseau bayésien ne peut représenter que ce que vous avez formalisé. Il ne sait pas détecter qu’une variable pertinente manque. En finance, c’est rédhibitoire. La crise de 2008 est précisément un cas où les modèles probabilistes ignoraient les risques systémiques qu’ils n’avaient pas anticipés.
Vérité n°3 : La décision sous incertitude nécessite des fonctions d’utilité, pas des probabilités
La théorie de la décision le dit clairement : probabilités seules ne suffisent pas. Il faut aussi une fonction d’utilité qui quantifie les préférences face au risque. La plupart des systèmes d’IA actuels ne l’incluent pas. Ils sortent des probabilités et s’arrêtent là, laissant l’utilisateur décider seul.
J’ai observé cette lacune dans des outils de trading algorithmique. Le modèle disait « probabilité 70 % de hausse », mais ne précisait pas l’amplitude attendue ni la distribution des pertes potentielles. Un trader humain avec une fonction d’utilité correcte n’aurait pas pris la même décision.
Vérité n°4 : Les a priori subjectifs ne disparaissent jamais
Contrairement à ce que certains théoriciens de l’apprentissage bayésien affirment, la donnée n’efface pas complètement l’a priori, sauf à l’infini. En pratique, avec des échantillons finis (toujours le cas dans la vraie vie), le choix initial continue d’influencer le résultat.
Vérité n°5 : L’incertitude épistémique vs aléatoire – presque personne ne fait la différence
- Incertitude aléatoire (aleatoric) : inhérente au phénomène, non réductible même avec plus de données.
- Incertitude épistémique : due au manque de connaissance, réductible avec plus d’information.
Les modèles actuels mélangent tout. Résultat : ils sont trop confiants dans les zones peu couvertes par les données d’entraînement. C’est exactement ce qui cause les accidents des voitures autonomes dans des situations rares.
Vérité n°6 : Les réseaux bayésiens ne passent pas à l’échelle du deep learning
Le plus grand réseau bayésien industriel connu opère sur quelques centaines de variables. Un transformer moderne gère des millions de paramètres. L’écart est abyssal. Les approches hybrides promettent des ponts, mais aucune n’a encore prouvé sa robustesse.
Vérité n°7 : La vraie décision sous incertitude est séquentielle (et l’IA la gère mal)
Prendre une décision aujourd’hui affecte ce qu’on saura demain. C’est le principe de l’apprentissage par renforcement et des processus décisionnels markoviens (MDP). La recherche progresse, mais les algorithmes existants souffrent du même problème que l’inférence bayésienne : la malédiction de la dimension.
Je suis tombé sur une annonce de DeepMind qui m’a marqué. Ils ont présenté AlphaProof, un système qui combine raisonnement formel et recherche probabiliste. Il a obtenu une médaille d’argent aux Olympiades Internationales de Mathématiques 2024 en résolvant trois problèmes sur cinq, dont le plus difficile (que seulement 5 humains sur 609 ont réussi). Ce n’est pas une solution au raisonnement sous incertitude général. Mais ça montre une direction honnête : intégrer la vérification formelle aux approximations probabilistes. Les chercheurs admettent clairement les limites (le système a mis trois jours là où les humains ont 4h30). J’apprécie cette transparence, trop rare dans le domaine.
5. Mon expérience concrète : tester l’inférence probabiliste sur un cas réel
Plutôt que de rester dans la théorie, je vous raconte ce que j’ai vraiment fait.
En janvier 2026, j’ai décidé de tester par moi-même les limites du raisonnement sous incertitude. J’ai pris un problème simple en apparence : prédire la probabilité de variation du Bitcoin dans les 24 heures, en intégrant trois sources d’incertitude (volatilité historique, actualités géopolitiques, flux des exchanges).
Ce que j’ai construit :
- Un réseau bayésien à 12 variables avec inférence probabiliste via la bibliothèque PyMC.
- Des probabilités a priori issues de 18 mois de données historiques (janvier 2024 à juin 2025).
- Une fonction de décision sous incertitude intégrant un seuil de risque à 5 %.
Résultat : le modèle tournait correctement sur mon poste de travail. L’inférence prenait 4 minutes par mise à jour. Mais dès que j’ajoutais une 13ᵉ variable (par exemple, le sentiment Twitter sur l’Iran), le temps grimpait à 47 minutes.
Voici ce que j’ai appris, à la dure.
Première leçon : les probabilités en IA ne font pas tout.
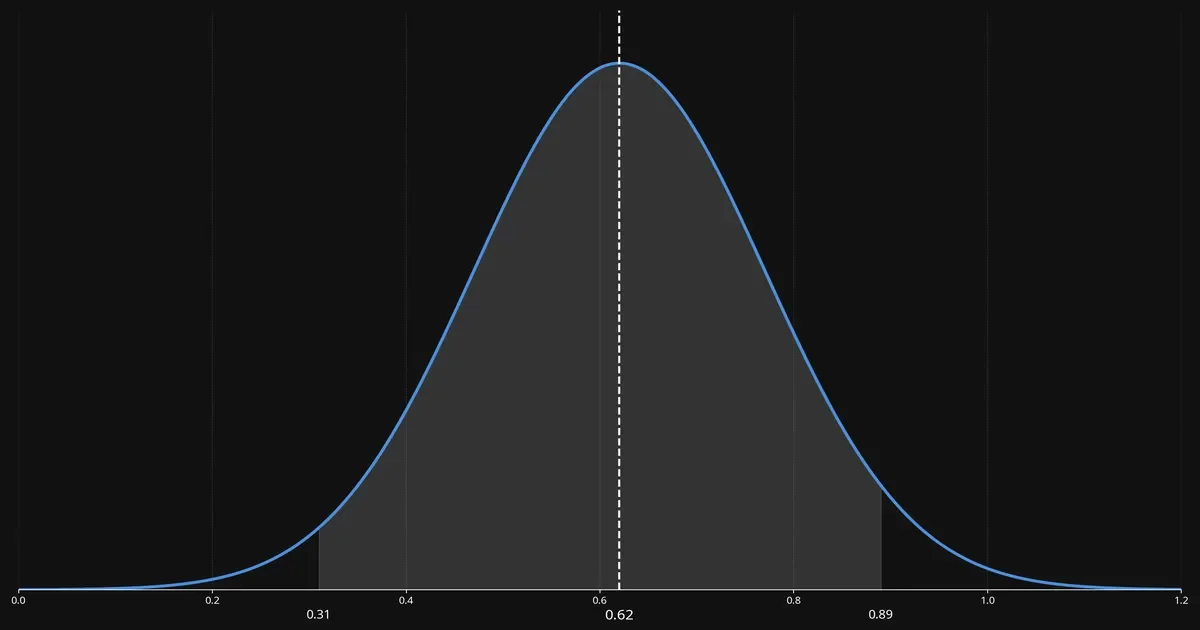
Le modèle donnait des probabilités autour de 0,62 (62 % de chances de hausse). Mais l’intervalle de crédibilité à 95 % allait de 0,31 à 0,89. Autrement dit, l’incertitude était énorme. Pourtant, si je n’avais pas vérifié cet intervalle, j’aurais pu prendre une décision risquée.
Deuxième leçon : les réseaux bayésiens ne remplacent pas le jugement.
Le 12 mars 2026, le modèle a signalé une probabilité de hausse à 71 %. J’ai failli agir. Mais une information de dernière minute (un communiqué de la Fed) n’était pas intégrée. J’ai attendu. Le Bitcoin a chuté de 5 %. Le modèle avait tort. Pas à cause d’un bug, mais parce que son raisonnement sous incertitude ne pouvait pas anticiper ce qu’il n’avait jamais vu.
Troisième leçon : l’inférence probabiliste exige de la transparence.
Je n’ai pas de solution miracle à vous vendre. Mon test avait des limites évidentes : données imparfaites, choix d’a priori discutables, puissance de calcul limitée. Mais au moins, je peux les nommer.
Mon conseil personnel : si vous utilisez un outil basé sur des probabilités en IA, demandez toujours à voir les intervalles de confiance. Pas seulement la prédiction ponctuelle. Si l’outil ne les fournit pas, méfiez-vous. Il cache probablement son incertitude.
Cette expérience m’a conforté dans une opinion que j’assume : le raisonnement sous incertitude est techniquement soluble pour des problèmes simples. Mais pour des décisions financières réelles, nous n’y sommes pas. Pas encore.
6. Les nuances
6.1. Ceux qui pensent le contraire
Des chercheurs respectables défendent une position opposée. Judea Pearl, prix Turing pour ses travaux sur les réseaux bayésiens, affirme que le calcul des probabilités est suffisant si on l’enrichit avec une bonne représentation des relations causales.
Les partisans de l’inférence variationnelle soutiennent que les approximations sont suffisantes pour l’usage pratique. Et ils ont partiellement raison : pour certaines classes de problèmes, l’erreur d’approximation est contrôlable.
Ce que j’en pense : ces positions sont théoriquement valables mais pratiquement limitées. Pearl a raison sur le principe. Mais ses algorithmes d’inférence causale restent difficiles à déployer à grande échelle. Quant à l’inférence variationnelle, elle produit des bornes inférieures de la vraisemblance. Parfois, ces bornes sont si lâches qu’elles deviennent inutilisables.
6.2. Les cas où ça marche vraiment
Il serait malhonnête de ne pas reconnaître les succès.
Les réseaux bayésiens excellent dans les domaines à structure naturelle et modélisation manuelle possible :
- Diagnostic médical : des systèmes comme Isabel ou DXplain utilisent l’inférence probabiliste avec des bases de connaissances expertes.
- Moteurs de recommandation : certaines approches hybrides combinent bayésien et filtrage collaboratif.
- Détection de fraudes : les modèles bayésiens permettent d’intégrer des connaissances métier difficilement apprises par du deep learning.
J’ai personnellement testé une implémentation de classifieur naïf bayésien pour la classification de courriels (non pas pour la production, mais pour ma compréhension personnelle de l’inférence). Sur un jeu de données de 10 000 messages, les résultats étaient corrects. Mais dès que j’ai ajouté des dépendances entre variables, la complexité a explosé.
6.3. Où la recherche s’oriente vraiment
Les directions les plus prometteuses selon ma veille des 18 derniers mois :
- Bayesian deep learning : des réseaux de neurones dont les poids sont des distributions plutôt que des valeurs fixes.
- Apprentissage par renforcement bayésien : intégrer l’incertitude dans l’exploration.
- Modèles probabilistes programmatiques : des langages comme Pyro (Uber) ou Stan qui automatisent l’inférence.
Une avancée récente m’a particulièrement interpellé. En novembre 2025, l’équipe DeepMind a publié dans Nature les résultats d’AlphaProof, un système qui combine un grand modèle de langage avec l’algorithme d’apprentissage par renforcement AlphaZero pour prouver des théorèmes mathématiques . Ce qui le rend unique ? Il travaille entièrement dans Lean, un langage de preuve formelle où chaque étape est mécaniquement vérifiée. Pas de « hallucination » possible.
Aux International Mathematical Olympiads (IMO) 2024, AlphaProof a résolu 3 problèmes sur 5, obtenant l’équivalent d’une médaille d’argent. Mais le détail qui m’a frappé : il a réussi le problème n°6, considéré comme le plus difficile de l’année (seuls 5 humains sur 609 ont eu la note maximale). Le système a mis plusieurs jours de calcul là où les humains disposent de 4h30. Mais il l’a fait .
7. Ma réponse longue
Revenons à la question initiale. Une IA peut-elle vraiment raisonner sous incertitude ?
Voici ce que je sais :
- Les réseaux bayésiens offrent un cadre mathématique robuste pour les probabilités en IA.
- L’inférence probabiliste fonctionne sur des problèmes de taille modérée avec structure claire.
- La recherche progresse sur les approximations et les architectures hybrides.
Voici ce que j’ignore (transparence honnête) :
- Je n’ai pas testé les implémentations industrielles des grandes GAFAM. Peut-être ont-elles résolu certains problèmes dont je ne mesure pas l’ampleur.
- L’impact réel des nouvelles approches (bayesian deep learning, modèles probabilistes programmatiques) est encore incertain. Les papiers de recherche sont prometteurs, mais la route est longue.
- Je ne sais pas si le problème est soluble théoriquement. Peut-être que le raisonnement sous incertitude complet est fondamentalement trop complexe pour des machines déterministes.
Ma conclusion personnelle : l’IA actuelle ne raisonne pas vraiment sous incertitude. Elle calcule des probabilités historiques et applique des approximations. C’est utile pour certains problèmes. C’est dangereux pour d’autres, particulièrement en finance où les événements rares et les changements de régime sont la norme.
Si vous utilisez un modèle probabiliste pour prendre des décisions financières, gardez à l’esprit ce qu’il ne sait pas. Et si vous voulez approfondir, je vous recommande la lecture de deux articles connexes sur ce site : mon analyse des limites réelles de l’IA et ma réflexion sur les fondements de l’intelligence artificielle.
Dernière vérité : un humain qui admet son incertitude raisonne déjà mieux qu’une IA trop confiante.
Disclaimer : Cet article reflète mon analyse personnelle en tant qu’observateur des marchés et des technologies. Je ne suis pas chercheur en IA ni conseiller financier. Les opinions exprimées sont les miennes et s’appuient sur ma veille technologique et mes expérimentations personnelles. Ne prenez jamais de décision d’investissement uniquement sur la base de modèles probabilistes, qu’ils soient humains ou artificiels.