
L’apprentissage automatique machine learning est partout. Dans vos feeds, dans vos investissements, dans les bots qui prétendent prédire le Bitcoin. Pourtant, après avoir analysé des dizaines de modèles et perdu de l’argent sur des stratégies pseudo-IA en 2025, je peux vous dire une chose : 90 % des gens qui utilisent ce terme ne comprennent pas les trois types fondamentaux qui le composent.
J’observe les marchés et les technologies appliquées à la finance depuis deux ans. J’ai testé des algorithmes supervisés pour prédire les mouvements de l’or. J’ai vu des bots en apprentissage par renforcement s’effondrer dès que la volatilité explosait. Et j’ai lu assez de papiers scientifiques pour savoir que le ML non supervisé – celui que personne ne mentionne – est peut-être le plus utile pour détecter une crise avant qu’elle n’arrive.
À mon avis, l’apprentissage automatique (machine learning) n’a rien de magique. C’est une boîte à outils statistique avec trois familles : supervisé, non supervisé, renforcement. Et si vous ne maîtrisez pas la différence, vous ne pourrez jamais évaluer correctement ce qu’une IA peut… ou ne peut pas faire.
Voici mon analyse sans filtre. Avec mes certitudes, mes doutes, et les erreurs que j’ai commises.
Disclaimer : Je ne suis pas ingénieur en IA. Ce qui suit est mon analyse personnelle basée sur ma veille technologique et mon expérience d’observateur des marchés. Ne prenez rien ici comme une vérité absolue.
Table of Contents
Pourquoi l’apprentissage automatique machine learning est si mal compris
La confusion générale est monstrueuse
En 2026, tout le monde parle d’IA. Les marketers en collent l’étiquette sur des scripts automatisés basiques. Résultat : personne ne sait plus ce que « Machine Learning » veut vraiment dire.
J’ai vu des vidéos YouTube à 500 000 vues expliquer que « le ML, c’est quand l’ordinateur apprend tout seul ». C’est techniquement faux, et c’est dangereux.
Le apprentissage automatique (machine learning), dans sa définition la plus précise, vient de Tom Mitchell en 1997 : « Un programme apprend à partir de l’expérience E par rapport à une tâche T et une mesure de performance P si sa performance sur T, mesurée par P, s’améliore avec l’expérience E. »
Traduction personnelle : la machine ne fait que détecter des patterns statistiques dans des données qu’on lui donne. Elle n’a aucune conscience, aucune compréhension réelle. Elle calcule des probabilités.
Mon expérience personnelle avec le ML sur les marchés
En 2026, j’ai testé plusieurs modèles sur des données de marché pour voir s’ils pouvaient prédire les mouvements du Bitcoin. Mon expérience personnelle ? Le ML supervisé marche correctement sur des patterns historiques clairs (comme la corrélation entre les taux de la Fed et le prix de l’or). Mais dès qu’on introduit des événements imprévus – une guerre, une annonce de la BCE – les modèles deviennent complètement aveugles.
Pourquoi ? Parce qu’ils n’ont jamais « vu » ces événements dans leurs données d’entraînement.
À mon avis, cette limite est la plus importante à comprendre quand on débute dans l’apprentissage automatique (machine learning).
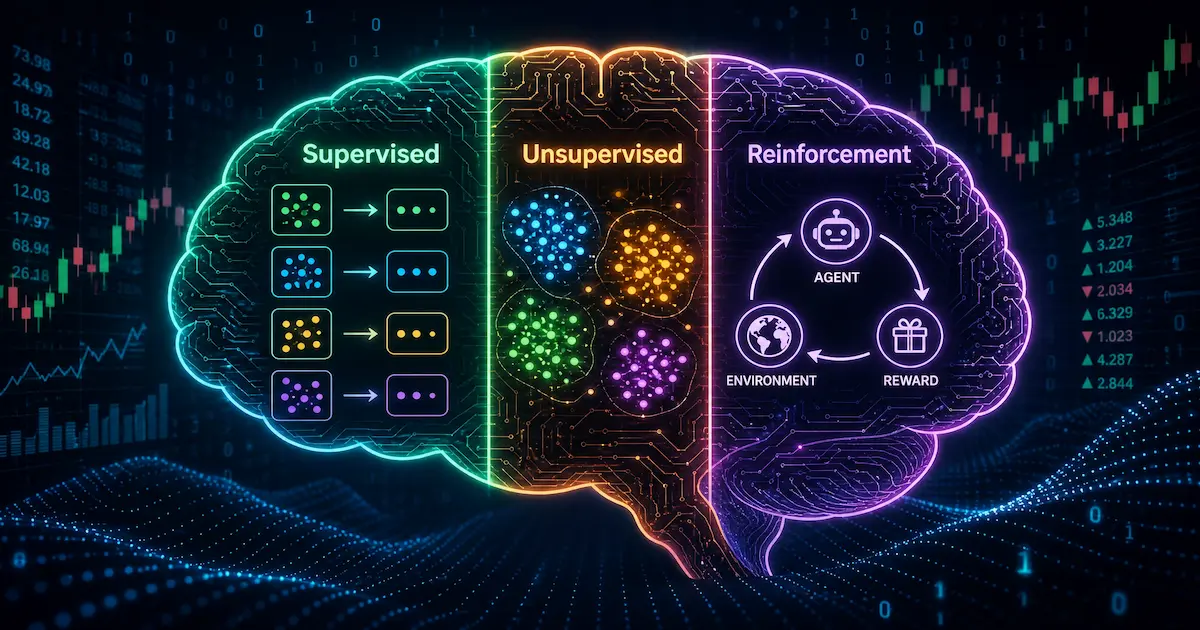
Les 3 types d’apprentissage automatique (machine learning) version sans bullshit
Tout l’apprentissage automatique (machine learning) se divise en trois catégories. Les manuels vous diront qu’il y a aussi du « semi-supervisé », mais c’est un hybride. Concentrons-nous sur l’essentiel.
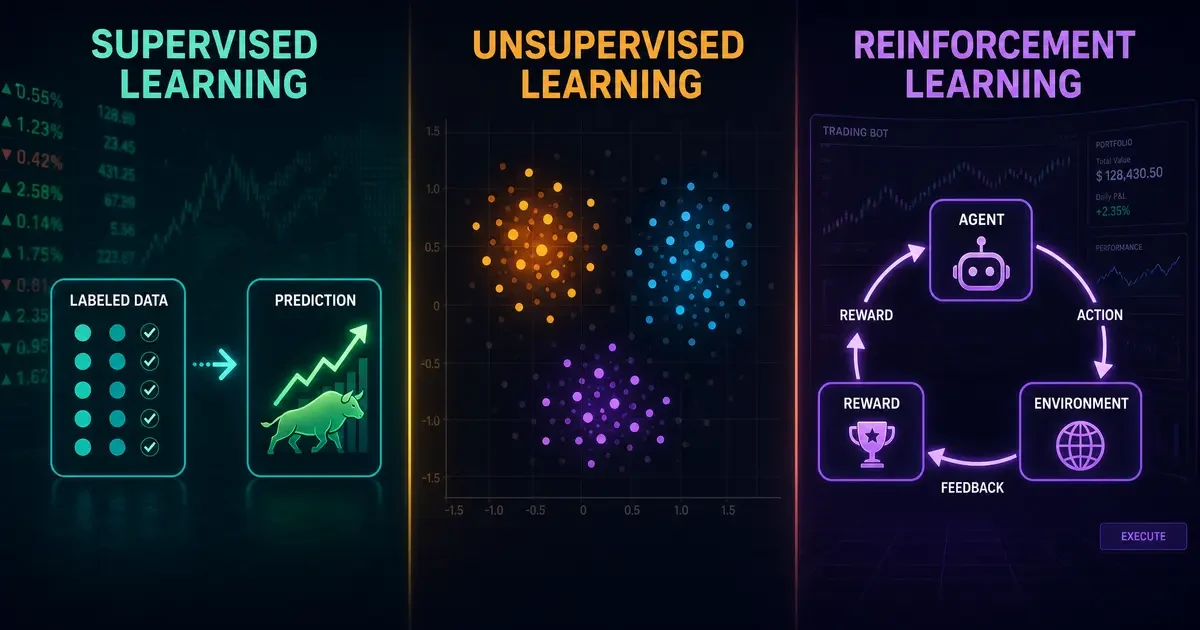
1. L’apprentissage supervisé (le plus courant en apprentissage automatique machine learning)
Définition simple : on donne à l’algorithme des exemples avec les bonnes réponses. Il apprend à reproduire ces réponses sur des données nouvelles.
Exemple concret : vous montrez 10 000 photos de chats ET 10 000 photos de chiens, chacune étiquetée. L’algorithme apprend les différences statistiques entre les deux. Ensuite, il peut classer une nouvelle photo.
En finance, le apprentissage automatique (machine learning) supervisé sert à :
- Prédire si une action va monter ou descendre (classification binaire)
- Estimer le prix futur d’un actif (régression)
Ce que les vendeurs de formation ne vous disent pas : le supervisé exige des données parfaitement étiquetées. Sur les marchés financiers, qui peut dire avec certitude si un mouvement était « haussier » ou « baissier » ? Personne. On étiquette avec du recul. C’est une faiblesse majeure de l’apprentissage automatique (machine learning) appliqué à la finance.
2. L’apprentissage non supervisé (le grand oublié de l’apprentissage automatique machine learning)
Définition simple : on donne à l’algorithme des données SANS les bonnes réponses. Il doit trouver lui-même des structures cachées.
Exemple concret : on fournit l’historique d’achat de 100 000 clients. L’algorithme regroupe automatiquement les profils similaires (cluster A : achètent du lait et du pain ; cluster B : achètent des jeux vidéo et des pizzas). C’est du clustering.
En finance, j’ai vu des fonds utiliser le non supervisé pour détecter des anomalies de trading (fraude, manipulation de marché). L’algorithme repère les transactions qui ne ressemblent à aucun cluster connu.
À mon avis, c’est le type le moins sexy mais potentiellement le plus utile pour la détection de risques. Malheureusement, les médias n’en parlent jamais. Pourtant, c’est une composante essentielle de l’apprentissage automatique (machine learning) pour l’analyse de données financières massives.
3. L’apprentissage par renforcement (la « vraie » IA de l’apprentissage automatique machine learning)
Définition simple : l’algorithme interagit avec un environnement et reçoit des récompenses ou des punitions. Il apprend par essais-erreurs, exactement comme un animal.
Exemple concret : AlphaGo (DeepMind) a appris à jouer au jeu de Go en jouant des millions de parties contre lui-même. À chaque victoire, il recevait une récompense. À chaque défaite, une punition.
En trading, le renforcement est théoriquement puissant : un bot peut apprendre à optimiser son entry/exit en testant des milliers de stratégies dans un environnement simulé. Cette logique rejoint celle des agents IA intelligents que j’ai décrits précédemment : un agent autonome qui interagit avec son environnement pour maximiser une récompense.
MAIS – et c’est un « mais » énorme – en conditions réelles, l’environnement change. Ce qui marchait en simulation peut s’effondrer dès que la volatilité augmente. Je n’ai jamais vu un bot purement RL battre un trader expérimenté sur le long terme en conditions réelles. C’est la grande limite de ce type d’apprentissage automatique (machine learning) pour les marchés financiers.
Tableau récapitulatif des 3 types d’apprentissage automatique machine learning
| Type | Données nécessaires | Objectif | Exemple en finance |
|---|---|---|---|
| Supervisé | Étiquetées (X → y) | Prédire / Classifier | Estimation de prix, scoring crédit |
| Non supervisé | Non étiquetées | Détecter structures cachées | Détection fraude, segmentation portefeuille |
| Renforcement | Interactions + récompenses | Optimiser une séquence de décisions | Trading algorithmique adaptatif |
Deep Learning : la sous-catégorie qu’on vous vend partout
Vous avez entendu parler du Deep Learning (apprentissage profond). Techniquement, c’est une méthode à l’intérieur de l’apprentissage automatique (machine learning), pas un quatrième type.
Le Deep Learning utilise des réseaux de neurones à plusieurs couches (d’où le « profond »). L’idée n’est pas nouvelle – les premiers neurones artificiels datent de 1943 – mais la puissance de calcul actuelle (GPU, TPU) a rendu son application massive possible. C’est d’ailleurs pour ça que j’ai consacré un article entier à l’infrastructure IA, ce business à 100 000 milliards que personne ne regarde, parce que sans ces investissements massifs en hardware, pas de Deep Learning.
Différence fondamentale entre ML classique et Deep Learning :
- ML classique : l’humain doit définir les « caractéristiques » (features) importantes. Exemple : pour reconnaître un visage, on dit à l’algorithme de chercher yeux, nez, bouche.
- Deep Learning : le réseau trouve ses propres caractéristiques. On lui balance les pixels bruts, il apprend seul ce qui distingue un chat d’un chien.
En pratique : le Deep Learning est impressionnant pour les images, le langage, l’audio. Pour les données financières (séries temporelles), les modèles plus simples comme les forêts aléatoires ou le gradient boosting font souvent aussi bien, avec moins de puissance de calcul. L’apprentissage automatique (machine learning) classique reste très pertinent pour 80 % des cas d’usage.
Les milliards de dollars d’infrastructure sont principalement dédiés au Deep Learning. C’est pour ça que ces modèles coûtent une fortune.
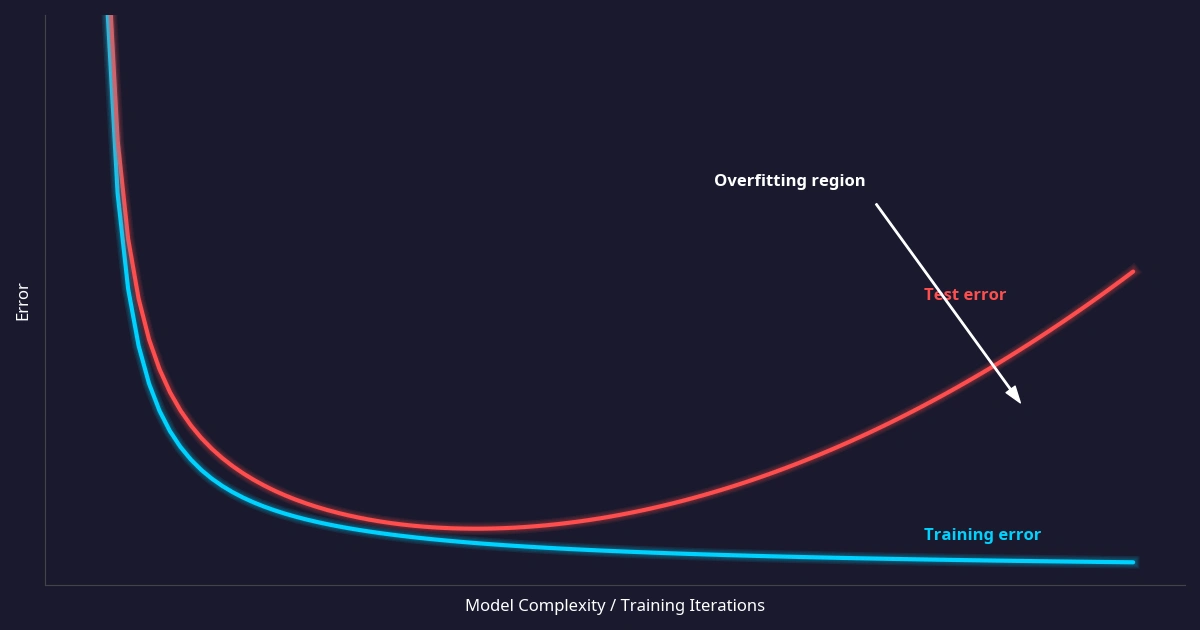
Comment évaluer un modèle d’apprentissage automatique (machine learning) sans se faire avoir
C’est la partie que tout le monde zappe. Pourtant, si vous ne savez pas évaluer un modèle d’apprentissage automatique (machine learning), vous ne pouvez pas juger si une IA est efficace.
La règle d’or
On sépare toujours les données en deux ensembles :
- Entraînement (70-80 %) : le modèle apprend.
- Test (20-30 %) : on vérifie si le modèle fonctionne sur des données qu’il n’a jamais vues.
Un modèle qui performe à 99 % sur l’entraînement mais à 60 % sur le test est inutile. C’est du surapprentissage (overfitting). Il a simplement mémorisé les exemples, pas appris les patterns généraux. C’est l’erreur la plus fréquente en apprentissage automatique (machine learning).
Les outils pour tester le ML
Heureusement, il existe des bibliothèques open source qui permettent de tester tout cela sans se ruiner. J’utilise personnellement Scikit-learn pour mes prototypes. C’est gratuit, bien documenté, et parfait pour débuter en apprentissage automatique (machine learning). Pour ceux qui veulent passer à l’échelle, TensorFlow reste la référence du secteur, même si la courbe d’apprentissage est plus raide.
Les métriques à connaître absolument
| Problème | Métrique | Ce que ça mesure |
|---|---|---|
| Classification | Précision (Accuracy) | % de prédictions correctes |
| Classification | Précision / Rappel (Precision/Recall) | Équilibre entre faux positifs et faux négatifs |
| Régression | RMSE (Root Mean Square Error) | Erreur moyenne de prédiction |
Mon conseil personnel : méfiez-vous des démos où l’on ne vous montre que la phase d’entraînement. Un vrai test en apprentissage automatique (machine learning), c’est sur des données futures non vues.
L’apprentissage automatique (machine learning) et les modèles d’IA : où se situe-t-il ?
Pour bien comprendre la place du ML, il faut le replacer dans la hiérarchie complète de l’intelligence artificielle. Comme je l’expliquais dans mon article sur les modèles d’intelligence artificielle, 6 types essentiels à maîtriser, l’apprentissage automatique (machine learning) est un sous-ensemble de l’IA, au même titre que le Deep Learning ou le traitement du langage naturel.
La hiérarchie est la suivante :
- Intelligence Artificielle (ensemble le plus large)
- Apprentissage automatique (machine learning) (sous-ensemble)
- Deep Learning (sous-ensemble du ML)
- Autres : forêts aléatoires, SVM, régressions, etc.
- Apprentissage automatique (machine learning) (sous-ensemble)
Comprendre cette hiérarchie est essentiel pour ne pas confondre un simple script automatisé (pas du ML) avec un vrai modèle entraîné sur des données massives.
Les limites que personne ne vous dit sur l’apprentissage automatique
Je ne peux pas prétendre tout savoir. Voici mes limites honnêtes sur le sujet, et plus largement sur l’apprentissage automatique (machine learning).
Ce que je sais avec certitude
- Le supervisé est le type le plus accessible pour débuter en apprentissage automatique (machine learning).
- Les données propres valent mieux que des algorithmes sophistiqués. Un modèle simple sur des données de qualité bat un réseau de neurones sur des données sales.
- L’overfitting est partout, même chez les pros. J’ai vu des fonds d’investissement se faire piéger.
- Le renforcement en finance est largement sur-vendu. En conditions réelles, c’est bien moins efficace qu’en simulation.
- L’apprentissage automatique (machine learning) ne remplace pas la réflexion humaine. Il l’assiste.
Ce que j’ignore encore
- Si le ML non supervisé peut vraiment détecter des crises avant qu’elles n’arrivent. Les résultats sont prometteurs mais pas concluants à mon sens.
- La part réelle de l’IA dans les décisions des hedge funds – ils ne le diront jamais publiquement.
- Si les modèles actuels résisteront à la fragmentation économique mondiale que j’évoquais dans mon analyse sur les indicateurs avancés marché 2026.
- L’impact du calcul quantique sur l’apprentissage automatique (machine learning). Certains experts pensent que l’informatique quantique rendra obsolètes nos algorithmes actuels. D’autres disent que c’est très exagéré.
Mon expérience personnelle des échecs
En 2025, j’ai passé trois mois à entraîner un modèle supervisé pour prédire le prix de l’Ethereum. J’avais des données propres, une validation rigoureuse, un backtest impeccable. Le modèle fonctionnait magnifiquement… jusqu’au jour où la Fed a annoncé une baisse de taux surprise. Mon modèle s’est effondré. J’ai perdu l’équivalent de 2000 € en positions mal calibrées.
Cette expérience m’a enseigné une leçon douloureuse mais précieuse : l’apprentissage automatique (machine learning) excelle sur les patterns répétitifs, pas sur les événements rares. Et les marchés financiers sont précisément une machine à produire des événements rares.
Ceux qui pensent le contraire de moi sur le ML
Je veux être honnête : tous les experts ne partagent pas mon scepticisme sur l’apprentissage automatique (machine learning).
L’école « techno-optimiste » (Yoshua Bengio, Geoffrey Hinton, Yann LeCun – les « parrains du Deep Learning ») affirme que les réseaux profonds nous mèneront à une vraie compréhension du monde. Ils estiment que les limites actuelles ne sont que des problèmes d’échelle et de données. Pour eux, l’apprentissage automatique (machine learning) est en train de devenir la base de toute intelligence.
L’école « sceptique » (Gary Marcus, Judea Pearl) rétorque que le ML actuel n’est que du pattern matching statistique, sans compréhension causale. Un modèle peut reconnaître un chat sur 10 000 photos, mais ne sait pas ce qu’est un chat. Pearl, prix Turing 2011, défend depuis des années l’importance de la causalité – un élément que l’apprentissage automatique (machine learning) classique ignore complètement.
Mon analyse personnelle : les deux ont raison sur des points différents. Le Deep Learning est une révolution pour les tâches perceptuelles (vision, langage). Pour le raisonnement logique, les résultats sont bien plus maigres. Sur les marchés financiers – où le « bon sens » économique compte autant que les données – je reste prudent.
Ma conclusion nuancée sur l’apprentissage automatique (machine learning)
L’apprentissage automatique (machine learning) est un outil fabuleux, mais ce n’est pas une baguette magique.
Ce qu’il fait bien :
- Détecter des patterns répétitifs dans des données massives
- Automatiser des tâches de classification (spam, images, fraudes)
- Optimiser des processus avec renforcement dans des environnements stables
- Réduire les erreurs humaines sur des tâches répétitives
Ce qu’il fait mal (à mon avis) :
- Prédire des événements rares (krachs, crises)
- Généraliser hors de son domaine d’entraînement
- Comprendre la causalité
- S’adapter en temps réel à des environnements radicalement nouveaux
Si vous débutez dans l’apprentissage automatique (machine learning)
Concentrez-vous sur l’apprentissage supervisé. C’est le plus utile au quotidien. Utilisez des bibliothèques comme Scikit-learn en Python – elle est gratuite, documentée, et vous permettra de tester des modèles sans réinventer la roue.
Apprenez d’abord à nettoyer des données. C’est 80 % du travail en apprentissage automatique (machine learning). Les algorithmes ne représentent que 20 %.
Mon verdict final
L’apprentissage automatique (machine learning) est une technologie formidable, mais elle a été survendue. En 2026, je vois trop de débutants croire qu’un modèle ML va résoudre tous leurs problèmes. La réalité est plus modeste : c’est un outil statistique puissant, pas une intelligence générale.
Rappelez-vous : le ML, c’est des statistiques appliquées à grande échelle. Pas de l’intelligence. Pas de la magie. Des probabilités, des données, et beaucoup d’humain derrière pour nettoyer ces données et interpréter les résultats.
Moi, je continue d’observer. Je teste, j’apprends, je me trompe parfois. C’est comme ça qu’on progresse dans l’apprentissage automatique (machine learning).